Introduction
For 8 weeks, I researched an advanced topic in the realm of game engine development. I was interested in learning about asynchronous asset streaming; Asynchronous referring to having the entire algorithm running in parallel to game logic and streaming referring to loading resources on-demand, instead of upfront. I was interested in this topic for a couple of reasons. I wanted to:
- Learn more about multithreading and async programming.
- Find out how open world games managed pieces of the world.
- Get familiar with common optimizations for textures and models.
What I did:
- Created a thread pool that accepts generic tasks and allows tracking them with
std::future - Optimized glTF models into a runtime format, composed of multiple files that can be loaded in parallel
- Created a handle abstraction for resources that may or may not be loaded
The Demo
The plan:
- Use the AABB of a model to determine which chunks it belongs to, building a 2D grid of cells with entities (I am using
enttin this project). - Calculate in which chunk the player belongs to and retrieve all nearby chunks
- Check the handles for the nearby models
- If the model is not loaded (which initially isn’t), queue it for loading
- If it is loaded, just get the resources and render it
- For chunks that the player just left streaming distance, free them and mark as unloaded
In my final demo, I created a scene populated with high resolution models sparsely around a low poly city environment. I added some graphs to the demo to also keep track of thread and memory usage:
In Detail
Implementing a Thread Pool
There are multiple examples of basic thread pool implementations online, like this one. I slightly modified the example above to return a std::future for keeping track of loading progress:
// Required: polymorphic container for Tasks with different return types
struct TaskInterface
{
virtual ~TaskInterface() = default;
virtual void Call() = 0;
}
template<typename Ret>
struct ConcreteTask : TaskInterface
{
std::packaged_task<Ret()> callable{};
virtual void Call() override { callable(); }
}
// Internally, the thread pool stores a queue of unique pointers to TaskInterface objects
template <typename Callable>
auto ThreadPool::QueueWork(Callable&& f)
{
using Ret = std::invoke_result_t<Callable>;
auto packaged = std::packaged_task<Ret()>(std::forward<Callable>(f));
auto future = packaged.get_future();
{
std::scoped_lock<std::mutex> lock { queue_mutex };
auto task = std::make_unique<ConcreteTask<Ret>>(std::move(packaged));
tasks.emplace(std::move(task));
}
worker_notify.notify_one();
return future;
}
This clever templated trick allows me to supply lambdas, callable objects and std::functions to the thread pool and get a std::future for the return type; which I found more practical than implementing a derived class for each type of task I required.
Referencing and Storing Resources
For referencing assets that may or may not be loaded into memory, simply using a shared pointer is not enough. My solution was to add an extra layer of indirection between references (or handles) to resources and the resources themselves:
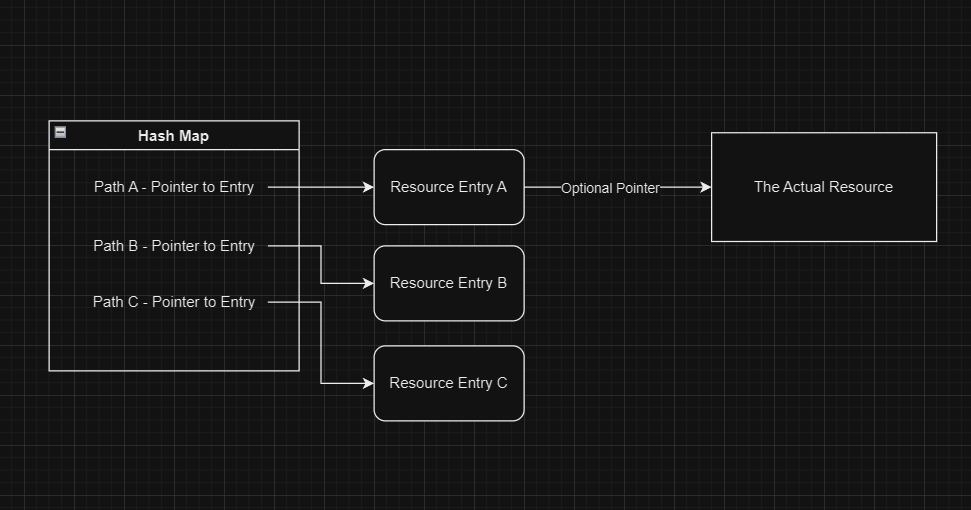
Essentially, my system would include Resource Entries, which contain the resource, state information and metadata; and Resource Handles, which are simply shared pointers to entries:
struct ResourceEntry
{
mutable std::mutex mutex; // protecting access to our resource
mutable Timer recently_used_timer; // used for caching
ResourceState state = ResourceState::UNLOADED;
std::string origin_path{};
size_t memory_consumption{};
std::type_index type{};
std::future<std::shared_ptr<void>> resource{};
std::shared_ptr<void> retrieve(); // getter for the resource
};
template<typename T>
class ResourceHandle {
private:
std::shared_ptr<ResourceEntry> ref{};
public:
std::shared_ptr<T> retrieve() const
{
return std::static_pointer_cast<T>(ref->retrieve());
}
};
Resource handles work like weak pointers: whenever you want to use one, you try to lock it (or retrieve it) to get a strong owning reference. The main way of identifying handles is through an asset’s path, which does pose a problem when you think about resources that are generated at runtime.
You may have also noticed I use std::shared_ptr<void>, which is not exactly the safest way to reference an object, but allows for storing all of my resources without deriving from a common base class. Internally, I use type indices to make sure that each entry is used with an appropriate resource handle type.
However, the main advantage of using an handle and entry abstractions like this is that we can lazily request for a resource: the entry acts like a thunk that only starts loading a resource when it is “retrieved” for the first time.
Runtime Format for glTF files
I found that it was very hard to parallelize glTF loading of files when I was using tinygltf for it. My solution was to preprocess all of my models into separate files, so that each worker thread would just work on its own file:
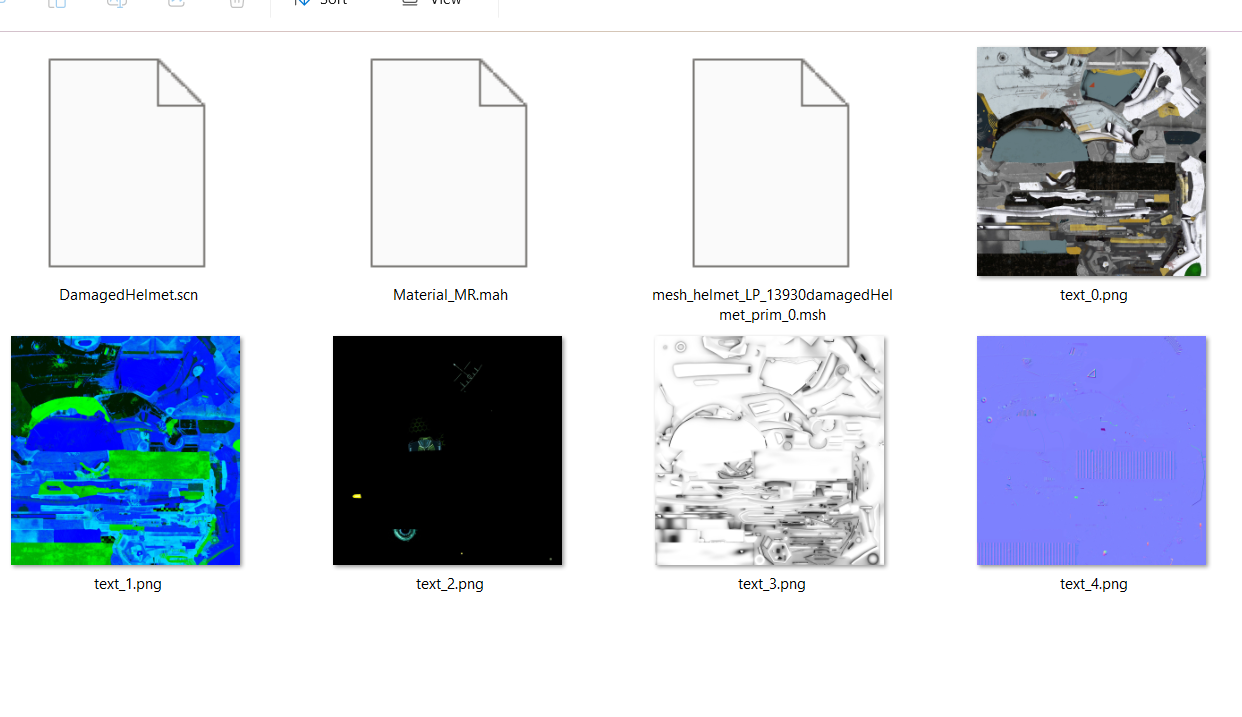
With it, I was able my load benchmark Bistro scene in only 10 seconds as compared to the usual 27 when I used tinygltf (note: the openGL renderer I was using for this project was not perfect)
The API
The entire system was managed by a StreamingManager class, that took care of storing all the Resource Entries as well as managing the queueing of loading tasks to the thread pool.
At startup, you register the resource types with a loader function of the type std::shared_ptr<void>(RequestCommands&, std::string_view):
//Initialize Loaders
resources.StreamManager().RegisterAssetLoader<Mesh>(LoadMeshAsset, "Mesh");
resources.StreamManager().RegisterAssetLoader<Image>(LoadImageAsset, "Image");
resources.StreamManager().RegisterAssetLoader<Material>(LoadMaterialAsset, "Material");
resources.StreamManager().RegisterAssetLoader<Model>(LoadSceneAsset, "Model");
A loader function, should be defined like:
std::shared_ptr<void> LoadImageAsset(ls::RequestCommands& commands, std::string_view path)
{
// Load image data from file...
// Maybe throw an exception if things go wrong...
auto image = std::make_shared<Image>(std::move(image_data), width, height, component);
renderer.QueueImageUpload(image);
return image;
}
Internally, this is called whenever we request a resource that is not loaded. However, to handle the case where resources may be dependent on other resources, I created the RequestCommands class:
std::shared_ptr<void> bee::LoadMaterialAsset(ls::RequestCommands& resources, const std::string_view& path)
{
// Open and parse material data file...
base_texture = Texture(resources.RequestDependency<Image>(base_path));
normal_texture = Texture(resources.RequestDependency<Image>(normal_path));
metallic_texture = Texture(resources.RequestDependency<Image>(metallic_path));
occlusion_texture = Texture(resources.RequestDependency<Image>(occlusion_path));
emissive_texture = Texture(resources.RequestDependency<Image>(emissive_path));
return std::make_shared<Material>(
base_texture, emissive_texture, normal_texture, occlusion_texture, metallic_texture,
base_scale, metallic_scale, roughness_scale
);
}
RequestCommands allows the loader to queue a loading task for a resource and returns a handle to that resource that will eventually be loaded.
Conclusion
Resource management for games is quite a complex optimization problem without a general solution. I was quite proud that my project was working, however it was lacking a lot of aspects that were out of scope for 8 weeks:
- Lack of LODs meant my example scene had to have a very small streaming distance.
- My renderer was not very optimized, especially since it could be improved to use block compression images.
- Specialized allocators are also another way you can optimize resource allocation and usage.
- The API I built was a bit convoluted to use and over-engineered.
However, I feel like this was a very good introduction to multithreading concepts, like mutexes and using futures. I explored many different strategies for implementing abstractions related to referencing resources; this gave me a good grasp of when it is necessary to settle for something simple (like shared pointers) and specialize my implementations for a specific use case, instead of generalizing.